诺福克郡
| 諾福克郡 Norfolk(英文) | |
|---|---|
郡 | |
 諾福克郡在英格蘭的位置 | |
| 主權國家 | |
| 構成國 | |
| 區域 | 英格蘭東[1] |
| 名譽郡 | |
| 面積 | 5,371 km² |
| • 排名 | 48個中排第5名 |
| 人口(mid-2016 est.) | 840,600 |
| • 排名 | 48個中排第24名 |
| 人口密度 | 157/km2(410/sq mi) |
| 民族 | 98.5% 白人 |
| 时区 | GMT(UTC) |
| • 夏时制 | BST(UTC+1) |
諾福克(郡)(英语:Norfolk,香港舊譯羅福[2]),英國英格蘭東部的郡。以人口計算,金斯林-西諾福克是第1大自治市鎮(Borough),諾里奇是第1大城市、第2大自治市鎮(亦是郡治),大雅茅斯是第1大鎮(Town),金斯林是第2大鎮。
諾福克實際管轄7個非都市區,因為沒有包含單一管理區,無論把它看待為名譽郡還是非都市郡,其人口和面積都分別是832,500和5,371平方公里。
目录
1 歷史
2 行政區劃
3 主要城市
4 地理
5 註釋
歷史
诺福克历史上是古代東盎格利亞王國(Kingdom of East Anglia)的重要组成部分。
行政區劃
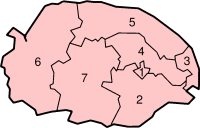
1. 諾里奇
2. 南諾福克
3. 大雅茅斯
4. 布羅德蘭
5. 北諾福克
6. 金斯林-西諾福克
7. 布羅克蘭
諾福克郡直接管轄7非都市區:諾里奇、南諾福克(South Norfolk)、大雅茅斯(Great Yarmouth)、布羅德蘭(Broadland)、北諾福克(North Norfolk)、金斯林-西諾福克(King's Lynn and West Norfolk)、布羅克蘭(Breckland)。
主要城市
英國城市地位:
- 諾維奇
地理
諾福克東臨北海,南與薩福克相鄰,西與林肯郡相鄰,西北部沿岸地區與林肯郡東南沿岸地區合組成沃什灣(The Wash)。

文森河

諾里奇座堂

诺福克海灘度假區

諾里奇

Britannia Pier戲院

great grandstand

皇家大戲院

當地伐木業








註釋
^ Hierarchical list of the Nomenclature of Territorial Units for Statistics and the statistical regions of Europe The European Commission, Statistical Office of the European Communities
^ 見香港九龍塘街道羅福道 Norfolk Road
| ||||||
坐标:52°37′41″N 1°17′58″E / 52.62806°N 1.29944°E / 52.62806; 1.29944
|


